Программный RAID в Linux. Часть 1
9
25100
11 декабря 2020 9:24
11/12/2020
Visitors have accessed this post 25100 times.
Автор — Максим Рязанов
Смотрите также — Wikipedia:RAID.
Избыточный массив независимых дисков (RAID) — это технология хранения, которая объединяет несколько компонентов дисков (как правило, дисководы или их разделы) в логическое устройство. В зависимости от реализации RAID эта логическая единица может быть файловой системой или дополнительным прозрачным слоем, который может содержать несколько разделов. Данные распределяются по дискам одним из нескольких способов, называемых «уровнями RAID», в зависимости от уровня избыточности и требуемой производительности. Таким образом, выбранный уровень RAID может предотвратить потерю данных в случае сбоя жесткого диска, повысить производительность или совместить обе задачи.
Несмотря на избыточность большинства его уровней, RAID не гарантирует безопасность данных. Он не защитит их в случае пожара, кражи компьютера или выхода из строя нескольких жестких дисков одновременно. Кроме того, установка системы с RAID является сложным процессом, который может уничтожить данные.
Поэтому обязательно сделайте резервную копию всех данных перед работой.
Кстати, если вы выбираете RAID-массив для хранения / резервирования данных, рекомендую также рассмотреть RAIDZ, реализованный через ZFS, более современную и мощную альтернативу программному RAID.
Стандартные уровни RAID
Существует много уровней RAID, мы же поговорим о самых часто используемых.
Использует чередование для объединения дисков. Хотя он не обеспечивает избыточность, все еще считается RAID. Но это позволяет получить большую выгоду в части скорости. Если в вашем случае увеличение скорости оправдывает возможность потери данных (например, для раздела подкачки), выберите этот уровень RAID. На сервере более подходящими являются массивы RAID 1 и RAID 5. Размер блочного устройства массива RAID 0 — это размер наименьшего раздела компонента, умноженный на количество его разделов.
Самый простой уровень RAID: прямое зеркалирование. Как и в случае с другими уровнями, его стоит применять, только если разделы находятся на разных физических дисках. Если один из этих дисков выйдет из строя, блочное устройство, предоставленное массивом RAID, продолжит работать в обычном режиме.
В примере будет использоваться RAID 1 для всего, кроме свопинга и временных данных.
Обратите внимание, что в программной реализации уровень RAID 1 является единственным вариантом для загрузочного раздела, поскольку загрузчики, читающие его, не понимают RAID, но компонентный раздел RAID 1 можно считать обычным разделом. Размер блочного устройства RAID 1 — это размер наименьшего раздела компонента.
Требует 3 или более физических дисков и сочетает избыточность RAID 1 с преимуществами RAID 0 в части скорости и размера. RAID 5 использует чередование, как RAID 0, но также хранит блоки четности, распределенные по каждому члену диска. В случае сбоя диска эти блоки четности используются для восстановления данных на заменяющем диске. RAID 5 может выдержать потерю одного члена диска.
Примечание: RAID 5 является распространенным выбором, благодаря сочетанию скорости и избыточности данных. Но, если один диск выйдет из строя и тоже самое произойдет со вторым до замены этого диска, все данные будут потеряны. Кроме того, при современных размерах дисков и неустранимых показателях ошибок чтения на потребительских дисках ожидается, что для перестройки массива 4 ТБ (то есть с вероятностью более 50%) будет хотя бы один URE. Из-за этого RAID 5 больше не рекомендуется индустрией хранения данных.
Требует 4 или более физических дисков и обеспечивает преимущества RAID 5, но с защитой от сбоев двух дисков. RAID 6 использует чередование, как и RAID 5, но хранит два отдельных блока четности, распределенных по каждому члену диска. В случае сбоя эти блоки используются для восстановления данных на заменяющем диске. RAID 6 может противостоять потере двух членских дисков.
Устойчивость к неисправимым ошибкам чтения несколько лучше, потому что массив все еще имеет блоки четности при восстановлении с одного неисправного диска. Однако, учитывая накладные расходы, RAID 6 является дорогостоящим, и в большинстве настроек RAID 10 в схеме far2 обеспечивает лучшие преимущества в скорости и надежности и поэтому является предпочтительным.
Вложенные уровни RAID
RAID 1 + 0 — это вложенный RAID, который сочетает в себе два стандартных уровня RAID для повышения производительности и дополнительной избыточности. Обычно его называют RAID10, однако Linux MD RAID10 немного отличается от простого уровня RAID.
RAID10 под Linux построен на концепциях RAID1 + 0, однако он реализует их как один уровень с несколькими возможными компоновками.
Макет рядом с X на дисках Y повторяет каждый фрагмент X раз на полосах Y / 2, но не требует, чтобы X делил Y равномерно. Куски помещаются практически в одно и то же место на каждом диске, на котором они отражаются, отсюда и название. Он может работать с любым количеством дисков, начиная с 2. Около 2 на 2 дисках эквивалентно RAID1, около 2 на 4 дисках — RAID 1 + 0.
Макет дальнего X на Y-дисках обеспечивает производительность чтения с чередованием в зеркальном массиве. Для этого каждый диск разделяется на две части, скажем, переднюю и заднюю, и то, что записывается на переднюю часть диска 1, отражается на обратной стороне диска 2, и наоборот. Это дает возможность чередовать последовательные операции чтения, благодаря которым RAID0 и RAID5 получают свою производительность.
Недостаток в том, что последовательная запись немного снижает производительность из-за расстояния, которое диск должен искать до другого раздела диска, чтобы сохранить зеркало. Однако RAID10 в схеме дальнего 2 предпочтительнее многоуровневых RAID1 + 0 и RAID5, если важны скорости чтения и доступность / избыточность. Тем не менее, он все еще не заменяет резервные копии. Смотрите страницу википедии для получения дополнительной информации.
Сравнение уровней RAID
| Уровень RAID |
Избыточность данных |
Использование физического диска |
Производительность чтения |
Производительность записи |
Устройств минимум |
| 0 |
No |
100% |
nX
Лучшая |
nX
Лучшая |
2 |
| 1 |
Yes |
50% |
До nX в многопотоке, иначе 1Х |
1X |
2 |
| 5 |
Yes |
67% — 94% |
(n−1)X
Превосходная |
(n−1)X
Превосходная |
3 |
| 6 |
Yes |
50% — 88% |
(n−2)X |
(n−2)X |
4 |
| 10,far2 |
Yes |
50% |
nX
Лучшая; наравне с RAID0, но с избыточностью |
(n/2)X |
2 |
| 10,near2 |
Yes |
50% |
До nX в многопотоке, иначе 1Х |
(n/2)X |
2 |
* Где n обозначает количество выделенных дисков.
Raid Layout (расположение данных на дисках в RAID)
- n (параметр, используемый по умолчанию): означает near copies (близко расположенные копии). Копии одного и того же блока данных имеют в различных устройствах аналогичные смещения, как видно на схеме ниже. Такая компоновка позволяет ускорить чтение и запись, как в массиве RAID 0.
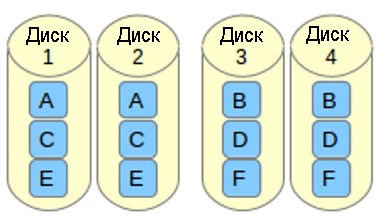
- o означает offset copies (смещение копий). Вместо того, чтобы дублировать куски данных в полосе, дублируются целые полосы, но они на каждом устройстве сдвинуты, так что дублируемые блоки находятся на разных устройствах с разными смещениями. То есть следующая копия на следующем диске находится на один фрагмент данных дальше. Чтобы использовать эту компоновку в вашем массиве RAID 10, добавьте параметр —layout=o2 в команду, с помощью которой создается массив.
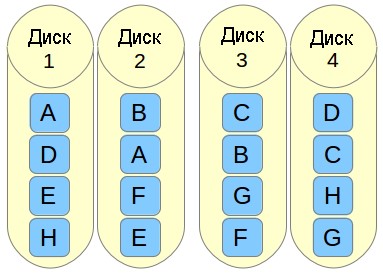
- f означает far copies (копии с сильно различающимися смещениями). Такая компоновка обеспечивает более высокую производительность чтения, но худшую производительность записи. Таким образом, это лучший вариант для систем, в которых операции чтения должны выполняться гораздо чаще операций записи. Чтобы использовать эту компоновку в вашем массиве RAID 10, добавьте параметр —layout=f2 в команду, с помощью которой создается массив.
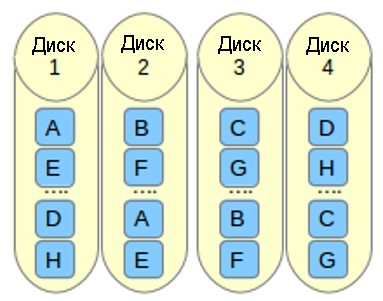
Число, которое расположено за n, f и o в параметре —layout, указывает, какое количество копий необходимо для каждого блока данных. Это значение по умолчанию равно 2, но оно может быть в диапазоне от 2 и до числа, равного количеству устройств в массиве. Указывая правильное количество копий, вы можете минимизировать влияние операций ввода/вывода на каждый отдельный диск.
Реализация
Устройствами RAID можно управлять различными способами.
Какой тип RAID используется у меня?
Поскольку программный RAID реализуется самим пользователем, его тип сразу известен.
Однако сложно отличить FakeRAID и настоящий аппаратный RAID. Как уже говорилось, производители часто неправильно различают эти два типа RAID. Лучшее решение в этом случае — запустить команду lspci и просмотреть выходные данные, чтобы найти контроллер RAID. Затем выполните поиск, чтобы увидеть, какую информацию можно найти о RAID-контроллере. Аппаратные RAID-контроллеры появляются в этом списке, а реализация FakeRAID — нет. Кроме того, настоящие аппаратные RAID-контроллеры часто бывают довольно дорогими (~ 400 долл. США), поэтому весьма вероятно, что выбор аппаратной конфигурации RAID внесет заметное изменение в цену компьютера.
Установка
Установите mdadm из официальных репозиториев. mdadm используется для администрирования чистого программного RAID с применением простых блочных устройств: базовое оборудование не предоставляет никакой логики RAID, только набор дисков. mdadm будет работать с любой коллекцией блочных устройств, даже необычных. Например, можно сделать массив RAID из набора флэш-накопителей.
Подготовка устройств
Предупреждение: следующие шаги уничтожат информацию на устройствах. Вводите команды с осторожностью!
Если устройство используется повторно или из существующего массива, удалите всю старую информацию о конфигурации RAID:
mdadm --misc --zero-superblock /dev/<drive>
Или на диске должен быть удален определенный раздел:
mdadm --misc --zero-superblock /dev/<partition>
Примечание:
- Установка суперблока раздела не должна влиять на другие разделы на диске.
- Из-за особенностей функциональности RAID очень сложно безопасно очистить диск полностью на работающем массиве. Подумайте, стоит ли это делать, прежде чем создавать его.
Создание таблицы разделов GPT
Настоятельно рекомендую предварительно разбить диски, которые будут использоваться в массиве. Поскольку большинство пользователей RAID выбирают жесткие диски> 2 ТБ, таблицы разделов GPT необходимы. Диски легко разбиваются с помощью gptfdisk.
- После создания типу раздела должен быть присвоен шестнадцатеричный код FD00.
- Если используется больший дисковый массив, рассмотрите возможность назначения меток дисков (disk labels) или меток разделов (partition labels), чтобы потом легче идентифицировать отдельный диск.
- Создание разделов одинакового размера на каждом устройстве является предпочтительным.
- Хороший совет — оставить около 100 МБ на конце устройства при разметке. Обоснование этого будет чуть ниже.
Таблицы разделов для MBR
Для тех, кто создает разделы на жестких дисках с таблицей разделов MBR, доступны следующие типы разделов:
- 0xDA (для данных не-fs — текущая рекомендация kernel.org);
- 0xFD (для массивов raid autodetect — было полезно перед загрузкой initrd для загрузки модулей ядра).
Примечание: Также можно создать RAID на сырых дисках (без разделов), но это не рекомендуется, потому что может вызвать проблемы при замене неисправного диска.
При замене вышедшего из строя диска RAID новый диск должен иметь точно такой же размер или больше, иначе процесс восстановления массива не будет работать. Даже жесткие диски одного производителя и модели могут незначительно отличаться в размерах. Оставив немного свободного места на конце диска, можно компенсировать эту разницу, что облегчает выбор модели сменного диска. Поэтому рекомендую оставлять около 100 МБ нераспределенного пространства в конце диска.
Создание массива
Предупреждение: версии ядра 4.2.x и 4.3.x в настоящее время имеют активную ошибку, которая не позволяет им собирать массив RAID10. Если у вас эти версии, можно использовать ядро версии 4.1.x, предоставленное linux-lts, до тех пор, пока ошибка не будет исправлена.
Используйте mdadm для построения массива. Несколько примеров приведены ниже.
Предупреждение: подставляйте правильные варианты / буквы диска в мои примеры, а не просто используйте copy + paste.
Примечание. Если это массив RAID1, предназначенный для загрузки из Syslinux, ограничение в syslinux v4.07 требует, чтобы значение метаданных было 1.0, а не значение по умолчанию 1.2.
Это пример построения массива RAID1 с двумя устройствами:
mdadm --create --verbose --level=1 --metadata=1.2 --raid-devices=2 /dev/md0 /dev/sdb1 /dev/sdc1
А это — построение массива RAID5 с 4 активными устройствами и 1 запасным устройством:
mdadm --create --verbose --level=5 --metadata=1.2 --chunk=256 --raid-devices=4 /dev/md0 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 --spare-devices=1 /dev/sdf1
Совет: —chunk использовался в примере, чтобы изменить размер куска со значением по умолчанию. См. Chunks: the hidden key to RAID performance для получения дополнительной информации.
А вот пример построения массива RAID10, far2 с двумя устройствами:
mdadm --create --verbose --level=10 --metadata=1.2 --chunk=512 --raid-devices=2 --layout=f2 /dev/md0 /dev/sdb1 /dev/sdc1
Совет: опции —homehost и —name могут использоваться для задания произвольного имени RAID-устройства. Они разделены двоеточием в полученном имени.
Массив создается под виртуальным устройством / dev / mdX, собирается и готов к использованию (в деградированном режиме). Можно сразу начать использовать его, пока mdadm повторно синхронизирует массив в фоновом режиме. Восстановление паритета может занять много времени.
Проверить прогресс создания можно так:
cat < /proc/mdstat
Обновить файл конфигурации
По умолчанию большая часть mdadm.conf закомментирована и содержит только следующее:
/etc/mdadm/mdadm.conf
DEVICE partitions
Эта директива говорит mdadm проверять устройства, на которые ссылается /proc/partitions, и собирать как можно больше массивов. Это хорошо, если вы действительно хотите запустить все доступные массивы и уверены, что не будут найдены неожиданные суперблоки (например, после установки нового устройства хранения данных).
А вот более аккуратный подход:
echo 'DEVICE partitions' > /etc/mdadm/mdadm.conf
mdadm --detail --scan >> /etc/mdadm/mdadm.conf
Он приведет к результату вроде следующего:
/etc/mdadm/mdadm.conf
DEVICE partitions
ARRAY /dev/md/0 metadata=1.2 name=pine:0 UUID=27664f0d:111e493d:4d810213:9f291abe
Это также заставляет mdadm проверять устройства, на которые ссылается /proc/partitions. Однако только активные устройства, имеющие суперблоки с UUID 27664…, собираются в активные массивы.Смотрите mdadm.conf (5) для получения дополнительной информации.
Сборка массива
После обновления файла конфигурации массив можно собрать с помощью mdadm:
mdadm --assemble --scan
Форматирование файловой системы RAID
Массив теперь можно отформатировать как любой другой диск, просто имейте в виду, что:
- Из-за большого размера тома не все файловые системы подходят (см. File system limits).
- Файловая система должна поддерживать рост и сжатие в режиме онлайн (see: File system features).
- Нужно рассчитать правильный шаг и ширину полосы для оптимальной производительности.
Расчет ширины шага и полосы (Calculating the Stride and Stripe Width)
В этом примере размер куска — это chunk size, а размер блока — block size.
Два параметра — шаг и ширина полосы — необходимы для оптимизации структуры файловой системы, чтобы вписаться в базовую структуру RAID. Они определяются размером блока RAID, размером блока файловой системы и количеством «дисков с данными».
Размер порции является свойством RAID-массива, определяемым при его создании. Текущее значение по умолчанию для mdadm — 512 КиБ. Его можно найти с помощью mdadm:
mdadm --detail /dev/mdX | grep 'Chunk Size'
Размер блока является свойством файловой системы, определяемой при ее создании. По умолчанию для многих файловых систем, включая ext4, установлено значение 4 КиБ. Смотрите /etc/mke2fs.conf для получения подробной информации о ext4.
Количество «дисков данных» — это минимальное количество устройств в массиве, необходимое для его полной перестройки без потери данных. Например, это N для массива raid0 из N устройств и N-1 для raid5.
Если у вас есть эти три величины, шаг и ширина полосы могут быть рассчитаны по следующим формулам:
stride = chunk size / block size
stripe width = number of data disks * stride
Пример 1. RAID0
Пример форматирования в ext4 с правильной шириной полосы и шагом:
- Гипотетический массив RAID0 состоит из 2 физических дисков.
- Размер куска составляет 64 КиБ.
- Размер блока составляет 4 КиБ.
Шаг = размер куска / размер блока. В этом примере математика: 64/4, поэтому шаг = 16.
Ширина полосы = количество физических дисков с данными * шаг. В этом примере математика 2 * 16, поэтому ширина полосы = 32.
mkfs.ext4 -v -L myarray -m 0.5 -b 4096 -E stride=16,stripe-width=32 /dev/md0
Пример 2. RAID5
Пример форматирования в ext4 с правильной шириной полосы и шагом:
- Гипотетический массив RAID5 состоит из 4 физических дисков; 3 диска с данными и 1 диск четности.
- Размер куска 512 КиБ.
- Размер блока составляет 4 КиБ.
Шаг = размер куска / размер блока. В этом примере математика 512/4, поэтому шаг = 128.
Ширина полосы = количество физических дисков с данными * шаг. В этом примере математика 3 * 128, поэтому ширина полосы = 384.
mkfs.ext4 -v -L myarray -m 0.01 -b 4096 -E stride=128,stripe-width=384 /dev/md0
Подробнее о шаге и ширине полосы см. RAID Math.
Пример 3. RAID10,far2
Пример форматирования в ext4 с правильной шириной полосы и шагом:
- Гипотетический массив RAID10 состоит из 2 физических дисков. Из-за свойств RAID10 в макете far2 оба считаются дисками данных.
- Размер куска 512 КиБ.
mdadm --detail /dev/md0 | grep 'Chunk Size'
Chunk Size : 512K
Шаг = размер куска / размер блока. В этом примере математика 512/4, поэтому шаг = 128.
Ширина полосы = количество физических дисков с данными * шаг. В этом примере математика равна 2 * 128, поэтому ширина полосы = 256.
mkfs.ext4 -v -L myarray -m 0.01 -b 4096 -E stride=128,stripe-width=256 /dev/md0
На этом на сегодня с RAID закончим. Продолжение — в следующей части.
От редакции
Если вам интересно посещать бесплатные онлайн-мероприятия по DevOps, Kubernetes, Docker, GitlabCI и др. и задавать вопросы в режиме реального времени, подключайтесь к каналу DevOps by REBRAIN.
*Анонсы мероприятий каждую неделю
Практикумы для специалистов по инфраструктуре и разработчиков — https://rebrainme.com.
Наш Youtube-канал — https://www.youtube.com/channel/UC6uIx64IFKMVmj12gKtSgBQ.
Агентство Fevlake, проектируем и поддерживаем IT-инфраструктуры с 2012 года — https://fevlake.com.



