Упрощаем работу с оповещениями в zabbix — настраиваем теги
2
9755
14 августа 2020 15:06
14/08/2020
Visitors have accessed this post 9755 times.
Автор — Евгений Генеральчик
В любой системе мониторинга крайне сложно найти золотую середину по оповещениям. Это та идеальная ситуация, когда алертов достаточно и они приходят своевременно для качественного реагирования на них. И при этом вы не тонете под лавиной алертов, когда уже невозможно выделить среди них действительно важные.
Как же быть? Частично снизить количество уведомлений об инцидентах можно разграничением по группам пользователей.
Но настроить правила обработки действий при возникновении какой-либо проблемы в zabbix весьма непросто. Чтобы получать определенные уведомления, нужно привязываться к хостам, темплейтам, триггерам и, чем больше таких привязок, тем сложнее расчет сопоставлений всех этих параметров. А значит, в нем немудрено заблудиться, что приводит либо к неполучению нужных уведомлений либо к получению уймы ненужных.
Выходом является использование тегов.
В zabbix как к хостам, так и к триггерам можно привязывать теги и формировать правила оповещений уже по ним, что значительно упрощает этот процесс. Причем все теги указываются в виде Name: Value, что, хоть и кажется поначалу неудобным, впоследствии становится весьма полезным.
Давайте рассмотрим пример. Так выглядело одно из правил до использования тегов.
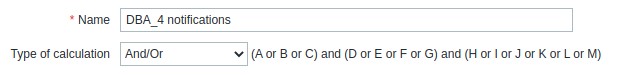
В приведенном примере указывались:
- совпадение групп хостов (A, B, C)
- совпадение темплейта (D, E, F, G)
- совпадение части имени триггера (H, I, J, K, L, M)
Т.е. для получения уведомления нужно чтобы хост находился в правильной группе хостов, на него был применен нужный темплейт, и в имени сработавшего триггера присутствовал специфический набор символов.
Разберем простую схему: у нас есть несколько окружений (prod, stage и dev), в каждом из них — несколько типов хостов (k8s-node, database) и несколько машин, которые сложно объединить в какой-то один тип (пусть будут other).
Начнем с добавления тегов для хостов. Каждый хост будет иметь два тега — env и type. env может принимать одно из значений prod, stage или dev. А type — соответственно, k8s-node, database или other. Уже на основе этих тегов можно поделить большую часть уведомлений для разных команд.
Однако даже с машин одного типа получать все уведомления может оказаться лишним. И здесь на помощь приходят теги для триггеров. Особенно это касается хитрых кастомных айтемов/триггеров. Имеет смысл добавить теги, чтобы разделить оповещения по командам и даже для дробления на уровни внутри команды. Для триггеров в этом примере был использован тег source (источник данных для триггера).
Набор триггеров с указанием нужных источников данных из тех темплейтов, которые попадали под изначальное правило, обрабатывали однотипные источники данных. Это позволило сократить теги после применения триггеров всего до двух:
A — env:prod, B — source:pgsql.
И вот так стало выглядеть наше правило с использованием тегов.

Разумеется, все теги добавлять руками долго и сложно, но для упрощения и ускорения рутинных действий уже давно есть темплейты и правила обнаружения или сделать это можно при помощи ansible при добавлении хоста во время установки агента.
К сожалению, в официальном мануале от zabbix не указано, как задавать теги, наверное, потому, что делать это еще проще, чем указывать значение макросов.
А вот почитать о том, как настраивать темплейты, можно тут.
А про правила обнаружения — здесь.
Давайте подытожим.
Что нам дает использование тегов:
- у нас теперь есть простые правила для работы с оповещениями;
- инфраструктура в системе мониторинга структурирована;
- обрабатывать уведомления становится проще.
По последнему пункту небольшое пояснение: под обработкой уведомлений я подразумеваю использование сервисов, занимающихся пересылкой, а иногда еще и систематизацией уведомлений (Opsgenie, Amixr, Pagerduty etc.).
От редакции
Если вам интересно посещать бесплатные онлайн-мероприятия по DevOps, Kubernetes, Docker, GitlabCI и др. и задавать вопросы в режиме реального времени, подключайтесь к каналу DevOps by REBRAIN.
*Анонсы мероприятий каждую неделю
Практикумы для специалистов по инфраструктуре и разработчиков — https://rebrainme.com.
Наш Youtube-канал — https://www.youtube.com/channel/UC6uIx64IFKMVmj12gKtSgBQ.
Агентство Fevlake, проектируем и поддерживаем IT-инфраструктуры с 2012 года — https://fevlake.com.



